
こんにちは。
ペタビットマーケティングでインターンをしている、神戸大学3回生 向井桃愛です。
ペタビットマーケティングはGoogle広告やMeta広告といったデジタル広告の運用を中心とするデジタルマーケティング企業です。インターンである私は、広告運用における業務改善や事前リサーチを担当しています。
本記事では、LLM開発プラットフォーム「Dify」と検索拡張生成技術「RAG」を活用して、社内向けのチャットボットを構築した経験について共有します。
特に、生成AIが抱える「ハルシネーション」(AIが確信を持って誤った情報を生成する現象)を徹底的に抑制し、高い精度と信頼性を実現するための設計思想を中心に解説します。
Contents
ミッション:なぜ精度が最優先事項なのか
今回与えられたミッションは、「社内の就業規則に関する質問に正確に回答するチャットボット」の開発でした。
就業規則という領域は、他の分野とは異なる深刻さがあります。曖昧な解釈や一般的な常識論での回答は、従業員のキャリアや待遇に直結するため、決して許されません。
万が一、誤った情報を提供してしまえば、法的なリスクにも発展しかねないからです。
したがって、開発の必須要件は以下の2点です:
- AIのハルシネーションを徹底的に抑制すること
- 回答の根拠を就業規則の文書のみに限定すること
つまり、教科書以外の知識に頼らないシステムの構築が絶対条件でした。
核となる技術:DifyとRAGの仕組み
Difyとは:ノーコード・ローコードで実現するLLMアプリケーション開発
Difyは、プログラミングの高度な知識がなくても、AIアプリケーション(特にチャットボット)を構築できる開発プラットフォームです。ビジュアル・ワークフロー・エディタ上でブロックを繋ぎ合わせるだけで、複雑な処理フローを組み立てられます。
このアプローチにより、ビジネス視点からの迅速なプロトタイピングが可能になります。今回のようなミッションクリティカルなプロジェクトに最適であり、プログラミング経験がない私にとっては、Difyが唯一の選択肢でした。
RAG(Retrieval-Augmented Generation):「知識の外部化」がもたらす精度の飛躍
RAGは、生成AIが誤った情報を生成するリスクを根本的に低減させるための革新的な技術です。
従来のLLMのアプローチ: インターネット上の膨大なデータから学習した知識を基に応答を生成します。この過程で、学習データに存在しない知識について「もっともらしい」内容を創作してしまう—これがハルシネーションです。
RAGのアプローチ: 指定された信頼できる文書(今回は就業規則)の中から、質問に関連する部分を検索(Retrieval)し、その見つけた情報のみを根拠にして回答を生成(Generation)します。
これは、まさに「AI向けのオープンブックテスト」です。教科書(就業規則)に記載されている内容のみが解答の源泉となるため、AIが無根拠な想像で答える余地が消滅します。
検索精度を高めるための工夫:HyDE(仮説的文書埋め込み)
単純なRAG構成だけでは、実際の運用において課題が生じました。
典型的なシナリオ:
- ユーザーが「有休について教えて」と質問
- 就業規則には「年次有給休暇」または「年休」と記載
- これらの用語の「表現のズレ」により、検索が失敗する
このような問題を解決するために、HyDE(Hypothetical Document Embeddings) という手法を導入しました。この手法は、NTTテクノクロス株式会社の技術ブログで紹介されていた先進的なアプローチです。
HyDEのメカニズム:
ユーザーの質問を受け取った際、まずLLMに「この質問に対して、就業規則ではこのような形で記載されているであろう」という仮の回答(Hypothetical Document)を一度生成させます。この仮の回答は、就業規則で実際に使用されている用語体系や文体に寄り添ったものになります。その結果、この仮の回答を検索クエリとして使用することで、ユーザーの元の質問では辿り着けなかった条文に到達できるようになります。
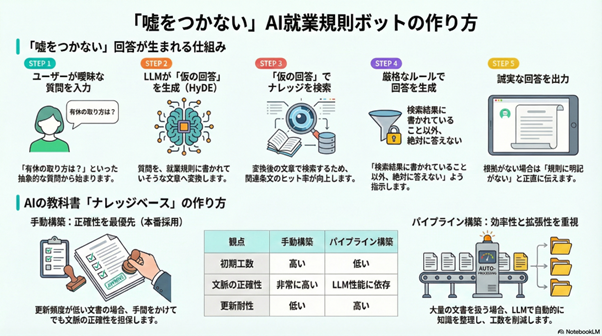
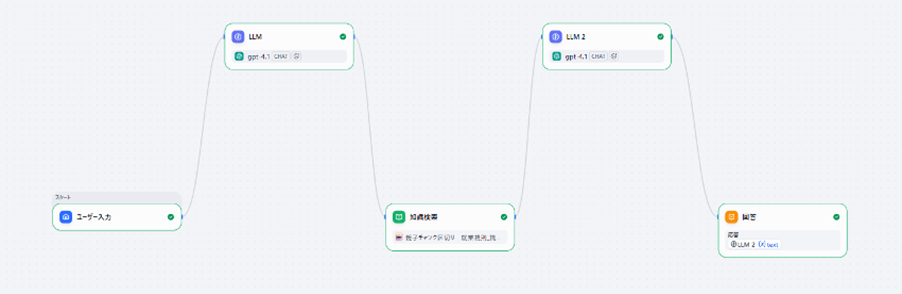
システムアーキテクチャ:5ステップの処理フロー
チャットボット全体は、以下の5段階で構成されています。
ステップ1:ユーザー入力
ユーザーが「有休について教えて」と入力します。
ステップ2:LLM(HyDE生成)
最初のLLMが、ユーザーの質問を解釈し、「年次有給休暇は、勤続年数に応じて付与される休暇であり、以下の規定に従います…」のような仮の回答を生成します。
ステップ3:知識検索
この仮の回答をベクトル化し、ナレッジベース(就業規則データ)の中から最も関連性の高い複数の条文を検索・抽出します。
ステップ4:LLM(厳格な回答生成)
検索で見つかった条文と、ユーザーの元の質問を組み合わせ、厳格なルールに従って最終的な回答を生成します。
ステップ5:ユーザーへの提示
生成された回答を提示します。
参考:LLM2で用いたプロンプト
以下は、LLM2(回答生成用LLM)に設定したシステムプロンプトの全文です。このプロンプトにより、AIが確実に「知っている情報のみを答える」という厳格なルールを遵守できるよう設計しました。
プロンプト内容のポイント:
- 情報源の限定:ナレッジベースの記載内容のみを回答根拠とする
- 推測の排除:曖昧な記載に対する補完や一般論の挿入を禁止
- 不確実性の明示:記載がない場合は明確に「分かりません」と回答
SYSTEM 以下の文脈だけを踏まえて質問に回答してください。
文脈:"""
{{#context#}}
"""
質問: """
{{#sys.query#}}
"""
あなたの唯一の情報源は、ナレッジベースに登録された就業規則文書です。次のルールを厳格に守って回答してください。
【1. 回答の原則】
- ナレッジベースに明確に記載されている事項のみ回答する。
- 記載が曖昧な場合、推測・一般論・外部知識を使用して補完してはならない。
- 文書内で根拠が確認できない場合は、必ず次のように回答する:
「この内容は就業規則に明記がありません。管理部へご確認ください。」
【2. 回答できない場合のテンプレート】
- 完全に情報がない場合:
「申し訳ありません。この内容は就業規則に明記がありません。管理部へご確認ください。」
- 一部のみ記載がある場合:
「ご質問のうち、以下の点は規則に記載があります:
(記載内容を要約)
その他の点は規則に明記がないため、管理部へご確認ください。」最も重要なポイント:ステップ4での厳格なルール設定
ステップ4の回答生成において、単に「分からなければ分からないと答える」では不十分です。ユーザーへの丁寧な対応を実現するため、プロンプト(AIへの指示)に以下の2つの条件分岐を組み込みました。
パターンA:完全に情報がない場合
質問に該当する情報がナレッジベースに一切見つからない場合、推測を完全に排除し、以下のように回答させます:
「申し訳ありませんが、このご質問の内容は就業規則に明記されていません。詳しくは人事・総務部までお問い合わせください。」
パターンB:一部のみ情報がある場合
質問内容の一部だけがナレッジベースに記載されている場合、段階的な回答構造を採用します:
「ご質問のうち、以下の点は就業規則に記載があります:[見つかった情報を提示] その他の点に関しましては、規則に明記がないため、人事・総務部へお問い合わせください。」
この細やかなルール設定により、AIが「知ったかぶり」をすることを防ぎ、ユーザーにとって親切で誠実なチャットボット体験を実現しました。
ナレッジベース構築:2つのアプローチの検証と選択
ナレッジベースとは、AIが回答を生成する際に参照する信頼できる情報のデータベースのことです。今回は就業規則の文書がそれに当たります。
ただし、長いPDF文書をそのままAIに渡しても、AIは効率的に処理できません。AIが理解しやすいよう、文書を意味のある小さな単位(「チャンク」)に分割する前処理が必要です。
本プロジェクトでは、この構築方法について、2つのアプローチを実装・検証しました。
方法1:手動構築(本番採用)
当初はパイプラインによる自動構築を想定していたのですが、予期せぬAPIキーの環境制約により、本番環境での自動化が困難であることが判明しました。そこで最終的に採用したのが、手動での構築です。
具体的な作業内容:
就業規則のテキストファイルを開き、意味の区切りが良い箇所に「——–」のような区切り文字を直接挿入していく、という地道な作業です。例えば、「慶弔休暇」に関する条文のまとまりが終わる箇所に「——–」を挿入し、その次の「休職」に関する条文と明確に分離する、といったアプローチです。
この手法が実務的に成立した理由:
- 就業規則の更新頻度が低く、頻繁なメンテナンスが不要
- 文書量がそこまで膨大ではない(効率よく手作業で処理可能)
- APIキーの環境制約という現実的な制約
プロジェクトの特性を総合的に判断した結果、初期工数はかかっても、文脈の正確性を最優先できるこの方法が最適だと判断できました。
方法2:ナレッジパイプラインによる自動構築(検証済み)
本来想定していた自動化の方法も検証しました。このアプローチは、Upgradetech社がZennで公開している記事を参考にしています。
Difyには「ナレッジパイプライン」という機能があり、これを活用すると文書の取り込みからチャンク分割までを自動化できます。具体的には以下のノードを連結します:
- Dify Extractor: 文書からテキストを抽出
- LLM ノード: 文章の意味的なまとまりを判断し、分割指示を実行
- General Chunker: 実際にテキストをチャンク化
LLMノードには以下のようなプロンプトを与えます:
「文章の意味的なまとまりを判断して、適切な箇所に『——–』を挿入してください。各チャンクは、独立した意味を持つ情報単位になるように分割してください。」
検証設定:最大チャンク長は500文字、チャンク間の重複(オーバーラップ)は40文字に設定しました。
参考:LLMノードの役割とプロンプト設計
LLMノードでは、文書を意味的に適切な単位で分割するため、以下のプロンプトを設定しました。検証時の設定は、Jinja設定を有効化し、モデルにはGPT-4を使用しました。
以下のプロンプトは、複数のセクション(SYSTEM、USER等)で構成されています。各セクションの役割は以下の通りです:
- SYSTEM セクション: AIに与えるシステム役割と基本方針
- INPUT/DATA セクション: 処理対象のテキストと詳細な処理手順
- CONSTRAINTS セクション: 絶対に守るべきルール
- USER セクション: 入力データの形式と要件
- OUTPUT セクション: 出力形式の指定
SYSTEM input: data: "分割対象のテキスト"
{{ text }}
prompt: |
1. **テキストの全体構造を把握する:** 入力テキストを読み、章・節・段落の構造と主要なトピックを理解する
2. **意味的な境界を特定する:** 話題やテーマが切り替わる箇所、段落の境界、リストや表の範囲を特定する
3. **分割ポイントを決定する:** 文脈を維持しながら、各チャンクが自己完結するように分割ポイントを決定する
4. **チャンクを生成する:** 決定した分割ポイントでテキストを分割し、`--------`で区切って出力する
5. **品質確認:** 各チャンクが意味的に完結し、元のテキストの内容が完全に保持されていることを確認する
context:
domain: "テキスト分割・チャンク化"
role: "高度なナレッジベースを構築する専門家"
goal:
objective: "ユーザーからの質問に対して、システムが最も的確で過不足のない情報を参照できるように、テキストを分割する"
constraints: |
- **元のテキストの完全性を維持する:** テキストの内容を一切、変更・要約・削除してはいけません。
- **区切り文字の厳守:** チャンクの区切りには、必ず半角のハイフン8つ `--------` のみを使用してください。
- **適切な分割粒度:**
- **意味的なまとまり:** 話題やテーマが大きく切り替わる箇所で分割してください。章・節・項や、段落ごとの主題を意識することが重要です。
- **文脈の維持:** 文の途中や、意味のつながりが強い段落の間など、文脈が途切れる場所で分割してはいけません。
- **自己完結:** 各チャンクが、単体でもある程度の意味を成すようにしてください。
- **リストと表:** 関連性の高い箇条書きや表は、分断せずに一つのチャンクに含めるようにしてください。
- **余計な出力はしない:** `--------` で分割されたテキストのみを出力してください。
output:
format: "チャンク分割されたテキスト(`--------`で区切り)"
type: "テキスト"
message: "入力テキストを意味的に最適なまとまりに分割し、`--------`で区切って出力してください"
USER user: data:
description: "社内規則・文書の入力データ説明"
examples:
- "社内規則・規程・ポリシー文書"
- "業務マニュアル・手順書"
- "人事規定・就業規則"
- "コンプライアンス関連文書"
- "システム利用規約・ガイドライン"
- "FAQ・よくある質問集"
- "研修資料・教育コンテンツ"
requirements:
- "テキスト形式の社内文書"
- "任意の長さの規則・規程"
- "構造化された文書(章・節・条項等)"
- "検索・参照が想定される内容"2つの方法の比較表
| 評価軸 | 手動構築 | パイプライン構築 |
| 初期構築工数 | 高い | 低い |
| 文脈の正確性 | 非常に高い | LLM性能に依存 |
| 更新対応の容易性 | 低い | 高い |
| スケーラビリティ | 低い | 高い |
最終判断: APIキーの環境制約という現実的な課題に直面しましたが、今回のプロジェクトの特性(更新頻度が低く、文書量も限定的)を総合的に考慮した結果、初期工数はかかっても、文脈の正確性を最優先できる「手動構築」を本番採用とする判断に至りました。

まとめ:実践を通じて得られた学び
このチャットボット構築プロジェクトを通じて、私が最も深く学んだことは以下の一点です。
「最先端の技術構成をそのまま採用することよりも、プロジェクト固有の制約条件(APIキーの環境制約、更新頻度、データ量規模、信頼性要件など)を深く理解し、その状況下で最適な手法を選択することが、ビジネス価値を最大化する」
HyDEを用いたRAGの実装、ナレッジベース構築における2つの手法の検証、予期せぬ環境制約への対応など、これらを通じて以下を実感しました。
- 最新技術には長所と短所がある
- 理論と実務にはギャップがある
- 制約の中での意思決定こそが、実務家としての価値を高める
この経験は、今後のキャリアにおいて、状況に応じた的確な設計判断を下すための、大きな財産になったと確信しています。
教科書だけでは決して学べない、実践的で奥深い開発経験を積むことができました。このような貴重な機会をいただけたことに、心から感謝しています。
最後に:ペタビットマーケティングでは長期インターンを募集しています
本記事で紹介したプロジェクトのように、ペタビットマーケティングでは、実践的で意義のあるプロジェクトに挑戦できるインターンシップの場を提供しています。生成AI、デジタルマーケティング、データ分析など、様々な領域で成長の機会があります。
ご興味のある方は、こちらの採用ページをご覧ください。長期インターンの詳細情報が掲載されています。
最後までお読みいただき、ありがとうございました。